Converting a PDF to a CSV Table
Sheetloom provides a powerful feature to extract data from a PDF document and convert it to a queryable CSV table.
Multiple PDFs can be simultaneously uploaded and converted into one CSV table.
To do this requires a field map document defining header names and fields from the PDF document.
Conversion Stages
The following sets out the PDF to CSV conversion process workflow.
1. Upload a PDF
From the PDFs page click Upload PDF and select a file.
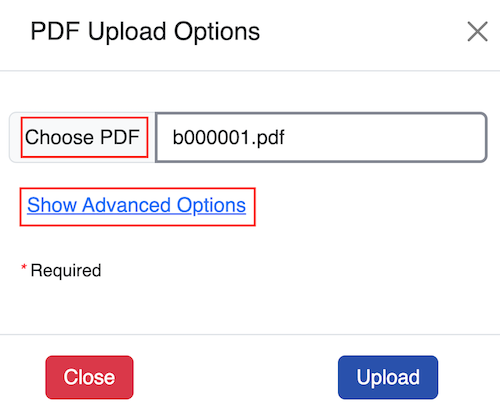
To change the name of the folder the PDF file will be stored in, click Show Advanced Options. The folder name can be changed from the PDF name that displays by default. In the example we change from b000001 (the company registration number) to Registration.
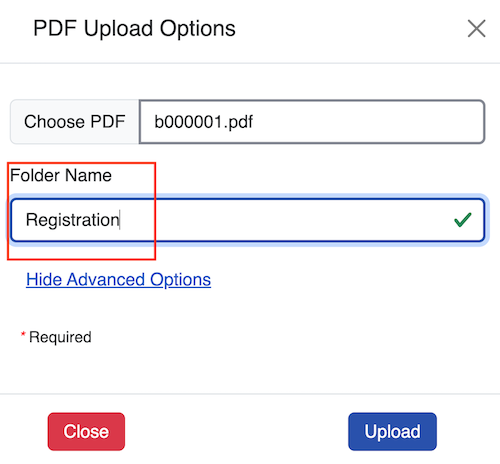
Select Upload. The Folder with the chosen name now displays in the PDFs page.
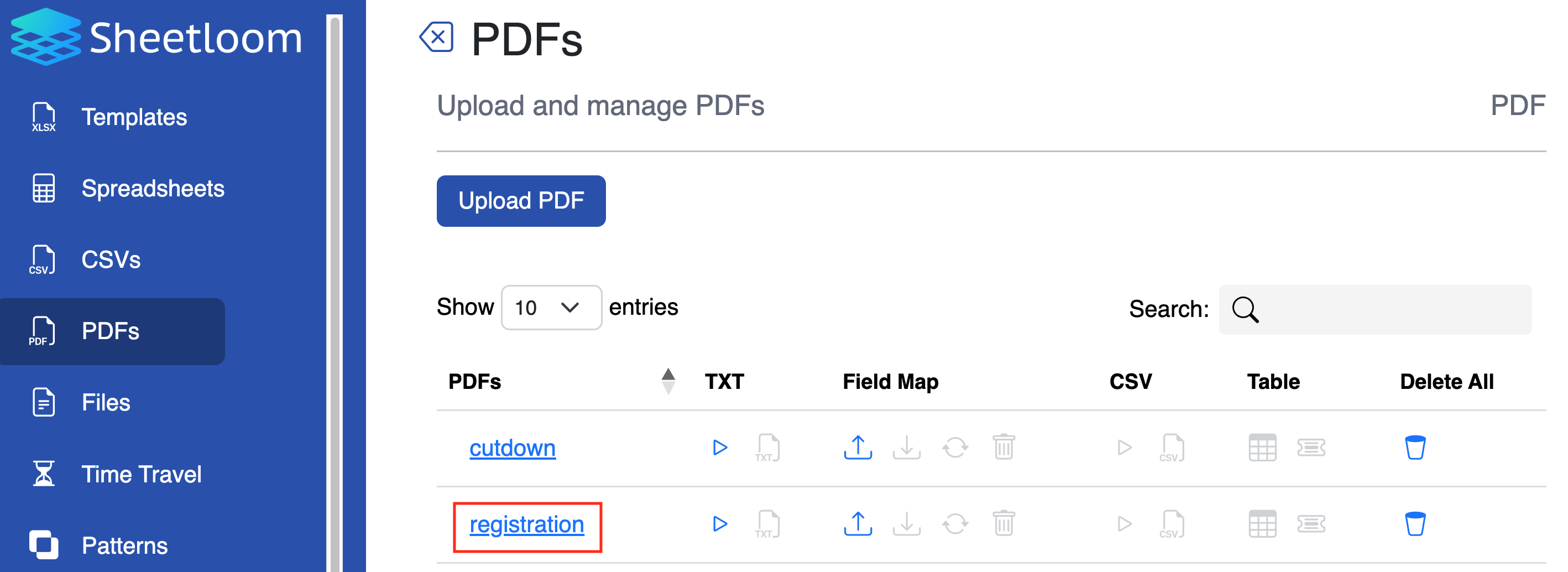
Changing the folder name to describe the content of the PDF being uploaded is recommended. For example, if the PDF is named as the company name, and contains registration details, changing name to Registration makes sense if other company PDFs will be appended later.
2. Append PDFs
Additional PDF files may be available to append immediately, or may not become available until later. The append is done the same way in either case.
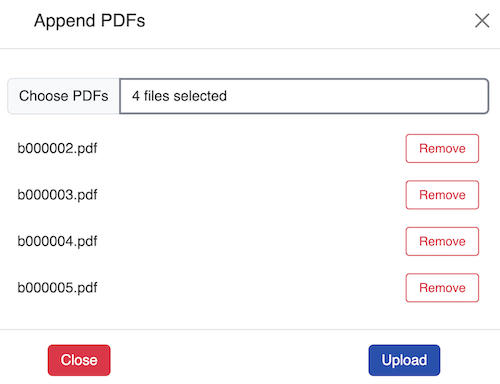
From the PDF page click on the PDF folder that was created in step 1 then click Append PDF. Click Choose PDFs and select the file or files to append, and click Open.
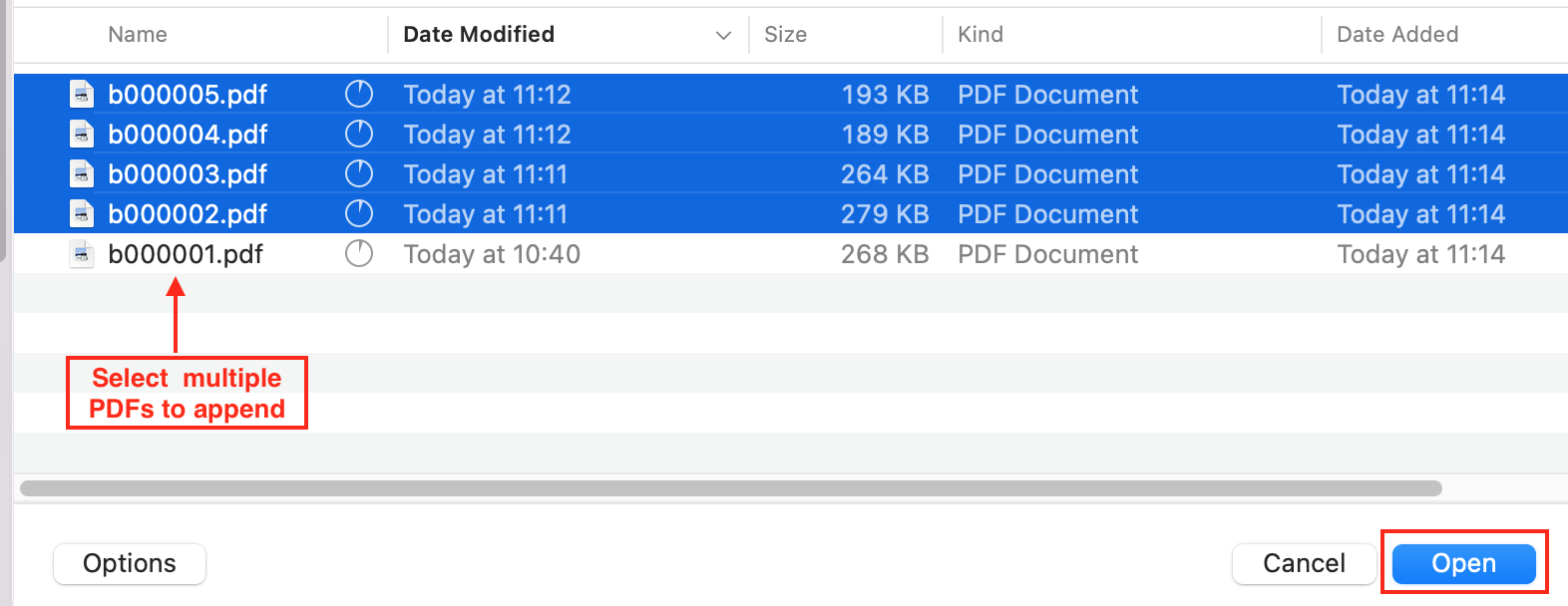
The files display in the dialogue box. Remove any if required then select Upload
The uploaded files are added to the folder.
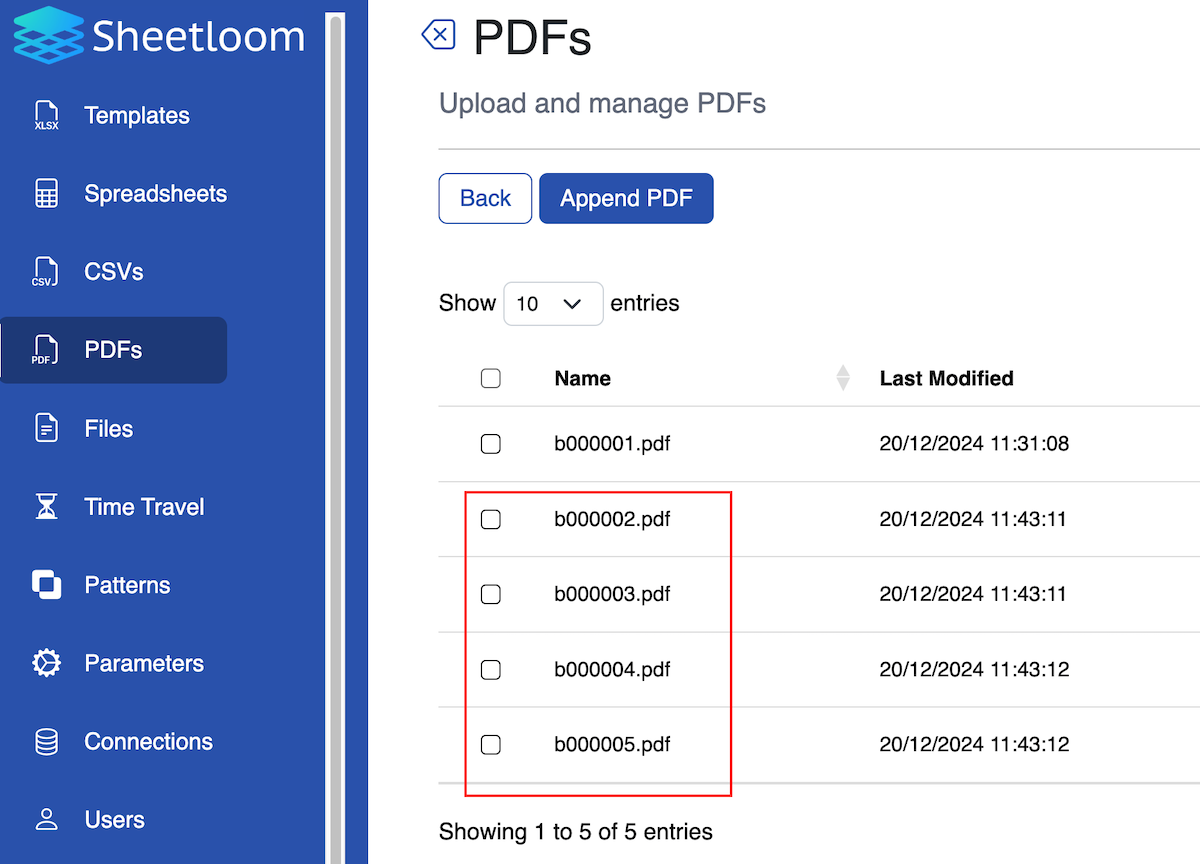
3. Extract Text Fields from PDFs
Uploaded PDFs are in binary format and text needs to be extracted from them before conversion.
Begin by generating a text file from the uploaded PDF file(s). To do this click the Play button in the TXT column. The process runs in a few seconds and a text document for each PDF is generated.
The TXT icon becomes live. Click on it to view a list of text documents that have been generated from the uploaded PDFs.
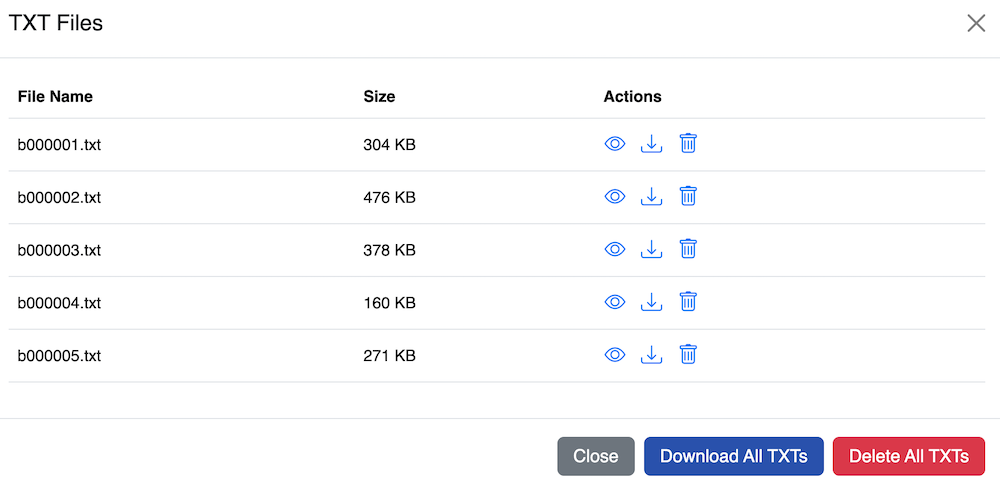
A text document can be viewed by downloading it or by clicking the eye icon.
4. Add a Field Map
This document is in YAML format and contains details of the CSV headers and field values to extract from the text document.
It can be externally produced, or produced within Sheetloom using the text files generated in step 3. See the field map page for configuration details.
From the PDF page click the Upload icon in the Field Map column. Select the field map file and upload it.
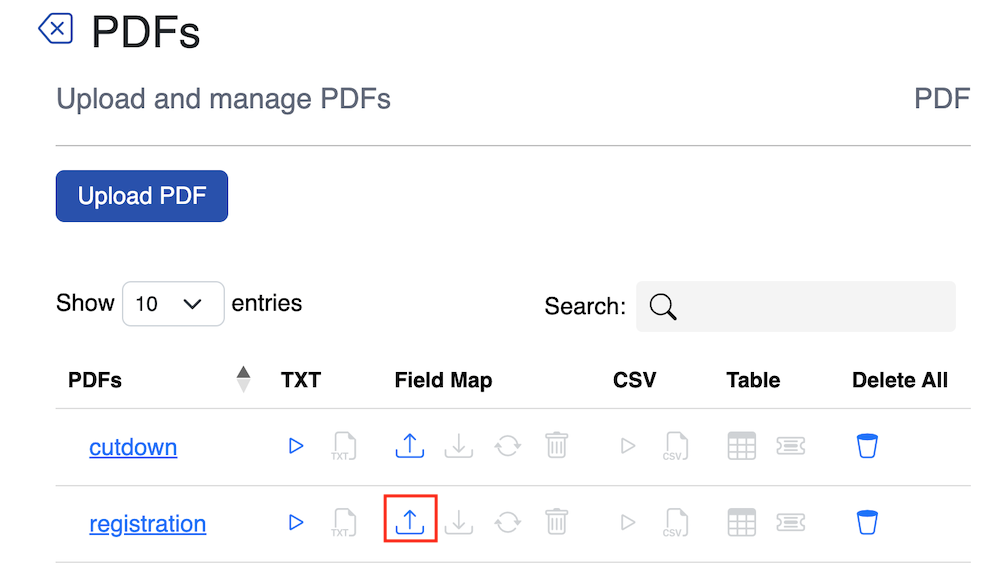
Mapping from the document to the target headers and values in the text file is automatically done when the map document is uploaded. To preview these click the text icon and the eye icon for the required text field from the pop-up that displays.
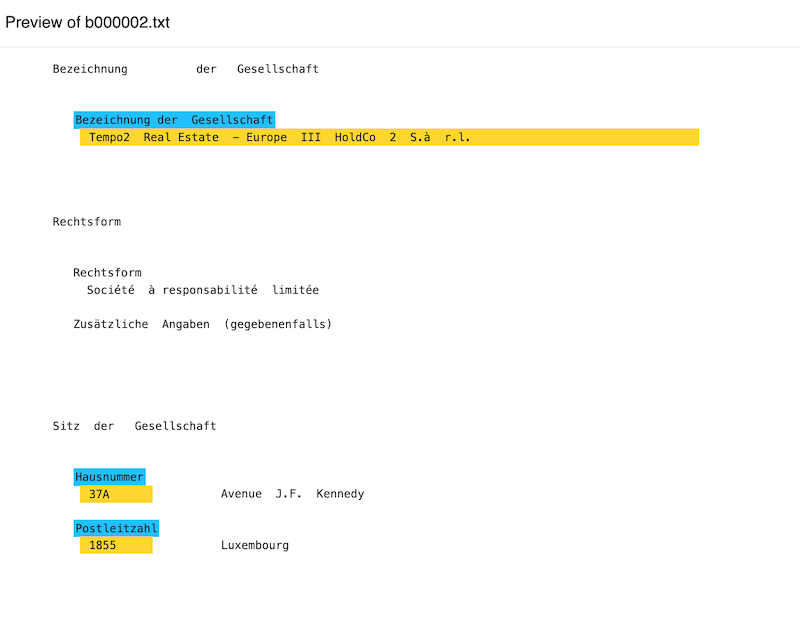
Mapped fields display in yellow. If the field was created in Sheetloom using a Header entry the field heading block also displays in blue.
The Field Map is typically prepared in advance but it can be created during the conversion workflow by following the instructions at Create a Field Map in Sheetloom
5. Generate a CSV from Text Files
A CSV file with the target headers and values from the text file can now be generated.
On the PDF page click on the Play button in the CSV column.
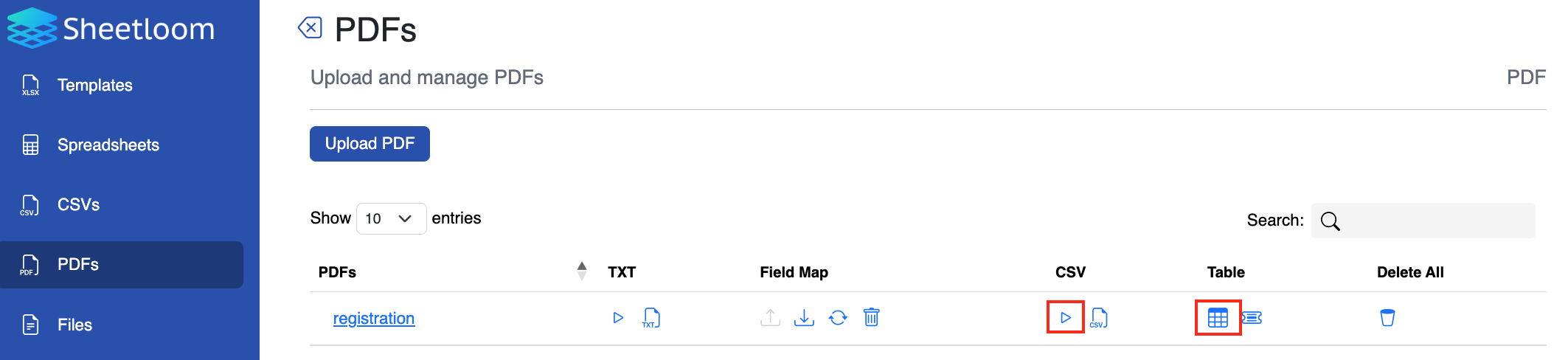
In a few seconds the CSV file is created. The CSV icon in the CSV column becomes live. Click it then the eye icon to generate a preview of the CSV showing the extracted columns.
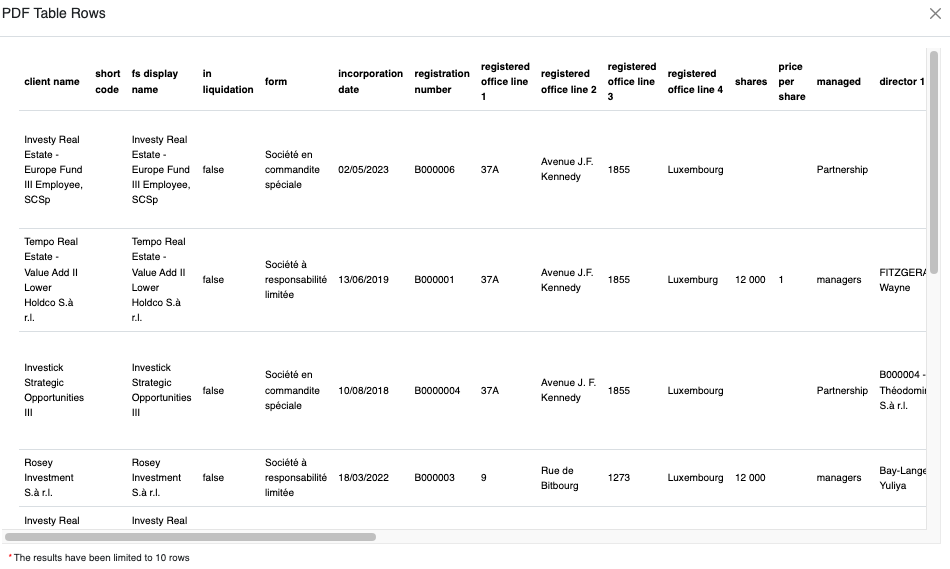
To preview the database table, select the table icon from the Table column.
The data is stored in a database table in Sheetloom called pdf_mytablename e.g., pdf_registration which can be referenced in a Stitch query like any other table. Click the list icon adjacent to the table icon in the Table column to display a sample query.
Fields added or removed in edits to the field map made after the CSV and database table have been created will not be reflected in the database table. A new conversion must be made.